
R has a amount of fast, stylish techniques to be a part of data frames by a widespread column. I would like to present you a few of them:
- R’s foundation
merge()functionality, - dplyr’s be a part of family of features, and
- details.table’s bracket syntax.
Get and import the information
For this case in point I’ll use a person of my favourite demo knowledge sets — flight hold off occasions from the US Bureau of Transportation Stats. If you want to comply with along, head to and down load facts for the time body of your selection with the columns Flight Date, Reporting_Airline, Origin, Locationand DepartureDelayMinutes. Also get the lookup table for Reporting_Airline.
Even so, download these two info sets — plus my R code in a single file and a PowerPoint explaining various types of info merges — right here:
Incorporates numerous details data files, a PowerPoint, and R script to accompany InfoWorld write-up. Sharon Machlis
To browse in the file with base R, I’d initial unzip the flight delay file and then import both flight hold off information and the code lookup file with study.csv(). If you happen to be working the code, the delay file you downloaded will possible have a diverse name than in the code underneath. Also, notice the lookup file’s unconventional .csv_ extension.
unzip("673598238_T_ONTIME_REPORTING.zip")
mydf <- read.csv("673598238_T_ONTIME_REPORTING.csv",
sep = ",", quote=""")
mylookup <- read.csv("L_UNIQUE_CARRIERS.csv_",
quote=""", sep = "," )
Next, I’ll take a peek at both files with head():
head(mydf)
FL_DATE OP_UNIQUE_CARRIER ORIGIN DEST DEP_DELAY_NEW X
1 2019-08-01 DL ATL DFW 31 NA
2 2019-08-01 DL DFW ATL 0 NA
3 2019-08-01 DL IAH ATL 40 NA
4 2019-08-01 DL PDX SLC 0 NA
5 2019-08-01 DL SLC PDX 0 NA
6 2019-08-01 DL DTW ATL 10 NAhead(mylookup)
Code Description
1 02Q Titan Airways
2 04Q Tradewind Aviation
3 05Q Comlux Aviation, AG
4 06Q Master Top Linhas Aereas Ltd.
5 07Q Flair Airlines Ltd.
6 09Q Swift Air, LLC d/b/a Eastern Air Lines d/b/a Eastern
Merges with base R
The mydf delay data frame only has airline information by code. I’d like to add a column with the airline names from mylookup. One base R way to do this is with the merge() function, using the basic syntax merge(df1, df2). It doesn’t matter the order of data frame 1 and data frame 2, but whichever one is first is considered x and the second one is y.
If the columns you want to join by don’t have the same name, you need to tell merge which columns you want to join by: by.x for the x dataframe column name, and by.y for the y one, such as merge(df1, df2, by.x = "df1ColName", by.y = "df2ColName").
You can also tell merge whether you want all rows, including ones without a match, or just rows that match, with the arguments all.x and all.y. In this case, I’d like all the rows from the delay data if there’s no airline code in the lookup table, I still want the information. But I don’t need rows from the lookup table that aren’t in the delay data (there are some codes for old airlines that don’t fly anymore in there). So, all.x equals TRUE aim all.y equals FALSE. Full code:
joined_df <- merge(mydf, mylookup, by.x = "OP_UNIQUE_CARRIER",
by.y = "Code", all.x = TRUE, all.y = FALSE)
The new joined data frame includes a column called Description with the name of the airline based on the carrier code.
head(joined_df) OP_UNIQUE_CARRIER FL_DATE ORIGIN DEST DEP_DELAY_NEW X Description 1 9E 2019-08-12 JFK SYR 0 NA Endeavor Air Inc. 2 9E 2019-08-12 TYS DTW 0 NA Endeavor Air Inc. 3 9E 2019-08-12 ORF LGA 0 NA Endeavor Air Inc. 4 9E 2019-08-13 IAH MSP 6 NA Endeavor Air Inc. 5 9E 2019-08-12 DTW JFK 58 NA Endeavor Air Inc. 6 9E 2019-08-12 SYR JFK 0 NA Endeavor Air Inc.
Join with dplyr
dplyr uses SQL database syntax for its join functions. HAS left join means: Include everything on the left (what was the x data frame in merge()) and all rows that match from the right (y) data frame. If the join columns have the same name, all you need is left_join(x, y). If they don’t have the same name, you need a by argument, such as left_join(x, y, by = c("df1ColName" = "df2ColName")) .
Note the syntax for by: It’s a named vector, with both the left and right column names in quotation marks.
update: Tea development version of dplyr has an additional by syntax: left_join(x, y, by = join_by(df1ColName == df2ColName)). Instead of a named vector with quoted column names, the new join_by() function uses unquoted column names and the == boolean operator.
If you’d like to try this out, you can install the dplyr dev version (1.0.99.90 as of this writing) with devtools::install_github("tidyverse/dplyr") gold remotes`::install_github("tidyverse/dplyr").
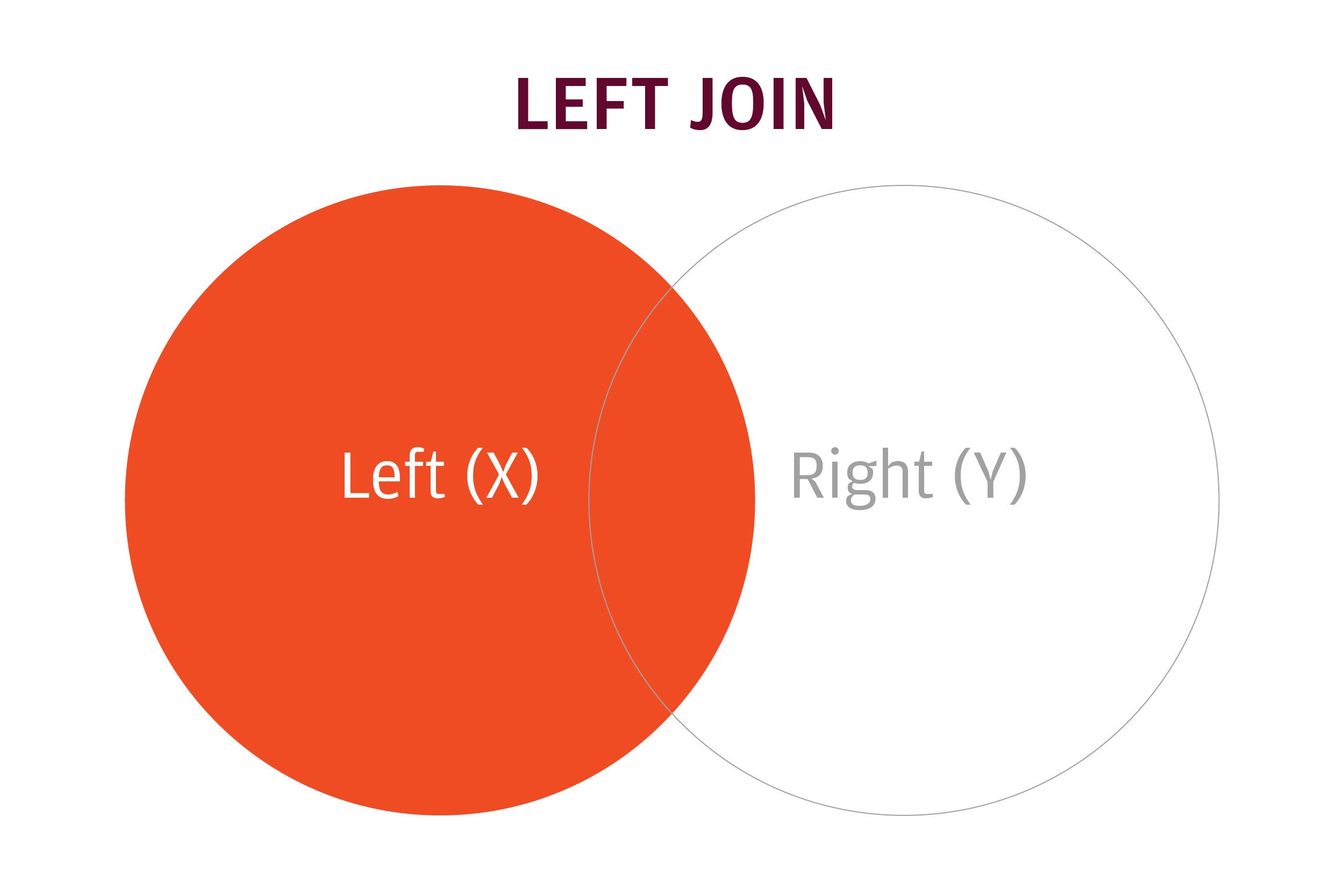 IDG
IDGA left join keeps all rows in the left data frame and only matching rows from the right data frame.
The code to import and merge both data sets using left_join() is below. It starts by loading the dplyr and readr packages and then reads in the two files with read_csv(). When using read_csv()I don’t need to unzip the file first.
library(dplyr)
library(readr)
mytibble <- read_csv("673598238_T_ONTIME_REPORTING.zip")
mylookup_tibble <- read_csv("L_UNIQUE_CARRIERS.csv_")
joined_tibble <- left_join(mytibble, mylookup_tibble,
by = c("OP_UNIQUE_CARRIER" = "Code"))
read_csv() creates tibbleswhich are a type of data frame with some extra features. left_join() merges the two. Take a look at the syntax: In this case, order matters. left_join() means include all rows on the left, or first, data set, but only rows that match from the second one. And, because I need to join by two differently named columns, I included a by argument.
The new join syntax in the development-only version of dplyr would be
joined_tibble2 <- left_join(mytibble, mylookup_tibble,
by = join_by(OP_UNIQUE_CARRIER == Code))
Since most people likely have the CRAN version, however, I will use dplyr's original named-vector syntax in the rest of this article, until join_by() becomes part of the CRAN version.
We can look at the structure of the result with dplyr's glimpse() function, which is another way to see the top few items of a data frame.
glimpse(joined_tibble) Observations: 658,461 Variables: 7 $ FL_DATE2019-08-01, 2019-08-01, 2019-08-01, 2019-08-01, 2019-08-01… $ OP_Exceptional_Provider "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL",… $ ORIGIN "ATL", "DFW", "IAH", "PDX", "SLC", "DTW", "ATL", "MSP", "JF… $ DEST "DFW", "ATL", "ATL", "SLC", "PDX", "ATL", "DTW", "JFK", "MS… $ DEP_Hold off_NEW 31, , 40, , , 10, , 22, , , , 17, 5, 2, , , 8, , … $ X6 NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,… $ Description "Delta Air Strains Inc.", "Delta Air Strains Inc.", "Delta Air …
This joined data established now has a new column with the title of the airline. If you operate a model of this code you, you may almost certainly see that dplyr was way more rapidly than foundation R.
Up coming, let's glance at a tremendous-speedy way to do be part of.
